Introduction to Partitions
Partitions allow the source data and aggregate data of a cube to be distributed among multiple server computers. Each partition in a cube can have a different data source. These data sources can reference relational databases on various computers. In addition, aggregate data of each partition can be stored on the Analysis server computer where the partition is defined, on another Analysis server computer, or in the same database as the partition's source data.
Every cube has at least one partition, which contains the cube's data; a single partition is automatically created for a cube when the cube is defined. When you create a new partition for a cube, the new partition is added to the set of partitions that already exist for the cube. The cube reflects the combined data contained in all of its partitions. The division of a cube into partitions is not visible to end users of the cube. You can use the Partition Wizard to create or edit a partition.
Note You can create multiple partitions in a cube only if you install Analysis Services for Microsoft® SQL Server™ 2000 Enterprise Edition.
Partitions are a powerful and flexible means of managing cubes, especially large cubes. For example, a cube containing sales information can contain a partition for the data of each past year and also partitions for each quarter of the current year. At the end of the year the four quarterly partitions can be merged into a single partition for the year.
Partitions can be stored using combinations of options for source data location,
Data Sources and Storage
Each partition has a
Each partition can store its aggregate data on the Analysis server computer where the partition is defined; this is the default. Partition aggregate data can also be stored on another Analysis server computer; this partition is a remote partition.
Each partition has a storage mode, which determines whether the partition's aggregate data is stored on an Analysis server computer or in the database specified in the partition's data source. The storage mode also determines whether a copy of the partition's source data is stored on the Analysis server computer.
Each partition can have a different aggregation design, which determines the number and contents of the aggregations created for the partition. With the Storage Design Wizard, you can tailor a partition's aggregation design by specifying constraints for storage utilization or increase in query performance. With the Usage-Based Optimization Wizard, you can perform these same actions, and you can also optimize the aggregation design based on queries previously sent to the partition's cube. You can select the queries by which to optimize.
The aggregate data is designed by using the Storage Design Wizard and the Usage-Based Optimization Wizard, but it is created when the partition or its cube is processed.
Object Hierarchy
Partitions are immediately subordinate to the cube. The data of a cube is the combination of all of the data of the cube's partitions. If a partition is added or deleted, and the cube is then processed, the data of the cube changes. Changes to a partition and subsequent processing can also cause the data of its cube to change.
In the object hierarchy, the following objects are immediately subordinate to the partition:
- Data sources
A partition has a single data source. By default, this is the data source of the partition's cube. A different data source can be selected from the data sources in the database or created during partition creation.
- Aggregations
A partition's aggregations apply to only that partition.
Caution When a cube contains multiple partitions, if the partitions are defined or handled incorrectly, it is possible for the cube to contain incorrect data. It is essential that you understand the considerations that apply to multiple-partition cubes before you create one.
Working with Partitions
You can use the Partition Wizard to create or edit a partition.
In Analysis Manager a local partition is identified by the following icon.

A remote partition is identified by the following icon.
After partitions are created, aggregations are usually the next objects to be created.
Structural changes to a cube, such as changes to its source data, fact table, or filter, require that you recreate the aggregations of all partitions in the cube.
You can merge two partitions that are in the same cube. The partitions to be merged must have the same storage mode and identical aggregation designs. The Partition Wizard provides options for copying the aggregation design of an existing partition.
If you are programming with Decision Support Objects (DSO), the class type associated with the partition is clsPartition.
Example: Four-Partition Cube
The following diagram shows how a four-partition cube can distribute its source data and aggregation data among five server computers. The activities of definition, storage design, processing, and querying are performed during four distinct time periods.
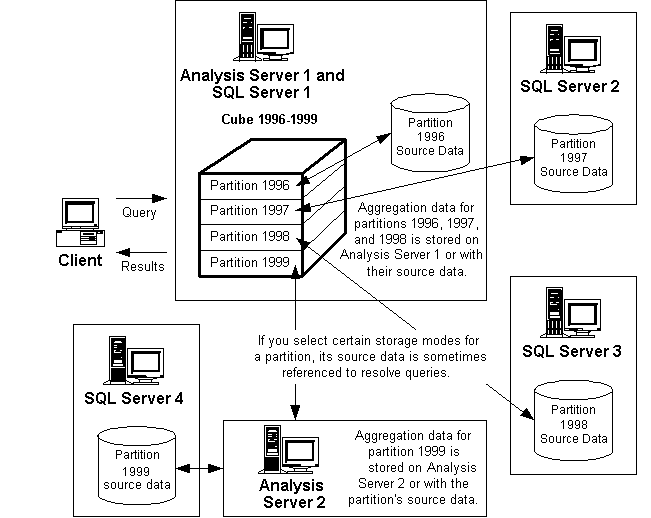
Cube 1996-1999 and its four partitions are defined on Analysis Server 1. The data sources of the partitions specify the locations of the source data of the partitions:
- The source data for Partition 1996 is stored on SQL Server 1, which is installed on the same computer as Analysis Server 1.
- The source data for Partition 1997 is stored on SQL Server 2.
- The source data for Partition 1998 is stored on SQL Server 3.
- The source data for Partition 1999 is stored on SQL Server 4.
Unlike partitions 1996, 1997, and 1998, Partition 1999 is defined as a remote partition. Its aggregate data is stored on a different Analysis server computer, Analysis Server 2. (Aggregate data is stored on the Analysis server computer only if the partition's storage mode is multidimensional OLAP (MOLAP) or hybrid OLAP (HOLAP); otherwise, data is stored in the same database as the partition's source data.)
Note Source data can be stored in databases of relational database products other than SQL Server. For more information, see Specifications and Limits.
Storage Design and Processing
For each partition in Cube 1996-1999, a storage mode is selected and aggregations are designed. The storage mode determines whether aggregate data will be stored on an Analysis server computer (that is, the storage mode is MOLAP or HOLAP) or with the source data of the partition (that is, the storage mode is relational OLAP (ROLAP)). The aggregation design determines the number of aggregations that are created.
When cube 1996-1999 is processed, aggregate data for its partitions is created. For partitions 1996, 1997, and 1998, aggregation data is stored on Analysis Server 1 or in the same databases as the source data of the partitions. For partition 1999, aggregation data is stored on Analysis Server 2 or in the same database as the partition's source data.
Queries
When a client that is connected to Analysis Server 1 issues a query to Cube 1996-1999, one or more of the following sources may be referenced to resolve the query:
- Client cache
Whenever the value of a requested cell can be found in or derived from the results of a prior query that are stored in client cache, the value is retrieved from the client cache.
- Aggregation data
If the value of a requested cell can be found in or derived from the aggregation data, the value is retrieved from the aggregation data.
- Source data
If the value of a requested cell cannot be found in or derived from the aggregation data, the value is retrieved from the source data, provided that the partition has a storage mode of HOLAP or ROLAP.
- Copy of source data stored on the Analysis server computer
If the value of a requested cell cannot be found in or derived from the aggregation data, the value is retrieved from a copy of the source data stored on the Analysis server computer, provided that the partition has a storage mode of MOLAP.
A single query can request data from multiple partitions.
The following diagram shows how a four-partition cube can distribute its source data and aggregation data among five server computers. The activities of definition, storage design, processing, and querying are performed during four distinct time periods.
Cube 1996-1999 and its four partitions are defined on Analysis Server 1. The data sources of the partitions specify the locations of the source data of the partitions:
- The source data for Partition 1996 is stored on SQL Server 1, which is installed on the same computer as Analysis Server 1.
- The source data for Partition 1997 is stored on SQL Server 2.
- The source data for Partition 1998 is stored on SQL Server 3.
- The source data for Partition 1999 is stored on SQL Server 4.
Unlike partitions 1996, 1997, and 1998, Partition 1999 is defined as a remote partition. Its aggregate data is stored on a different Analysis server computer, Analysis Server 2. (Aggregate data is stored on the Analysis server computer only if the partition's storage mode is multidimensional OLAP (MOLAP) or hybrid OLAP (HOLAP); otherwise, data is stored in the same database as the partition's source data.)
Note Source data can be stored in databases of relational database products other than SQL Server. For more information, see Specifications and Limits.
Storage Design and Processing
For each partition in Cube 1996-1999, a storage mode is selected and aggregations are designed. The storage mode determines whether aggregate data will be stored on an Analysis server computer (that is, the storage mode is MOLAP or HOLAP) or with the source data of the partition (that is, the storage mode is relational OLAP (ROLAP)). The aggregation design determines the number of aggregations that are created.
When cube 1996-1999 is processed, aggregate data for its partitions is created. For partitions 1996, 1997, and 1998, aggregation data is stored on Analysis Server 1 or in the same databases as the source data of the partitions. For partition 1999, aggregation data is stored on Analysis Server 2 or in the same database as the partition's source data.
Queries
When a client that is connected to Analysis Server 1 issues a query to Cube 1996-1999, one or more of the following sources may be referenced to resolve the query:
- Client cache
Whenever the value of a requested cell can be found in or derived from the results of a prior query that are stored in client cache, the value is retrieved from the client cache.
- Aggregation data
If the value of a requested cell can be found in or derived from the aggregation data, the value is retrieved from the aggregation data.
- Source data
If the value of a requested cell cannot be found in or derived from the aggregation data, the value is retrieved from the source data, provided that the partition has a storage mode of HOLAP or ROLAP.
- Copy of source data stored on the Analysis server computer
If the value of a requested cell cannot be found in or derived from the aggregation data, the value is retrieved from a copy of the source data stored on the Analysis server computer, provided that the partition has a storage mode of MOLAP.
A single query can request data from multiple partitions.
See Also
Designing Storage Options and Aggregations