The REFind and REFindNoCase functions return the location in the search string of the first match of the regular expression. Even though the search string in the next example contains two matches of the regular expression, the function only returns the index of the first:
<cfset IndexOfOccurrence=REFind(" BIG ", "Some BIG BIG string")>
<!--- The value of IndexOfOccurrence is 5 --->
To find all instances of the regular expression, you must call the REFind and REFindNoCase functions multiple times.
Both the REFind and REFindNoCase functions take an optional third parameter that specifies the starting index in the search string for the search. By default, the starting location is index 1, the beginning of the string.
To find the second instance of the regular expression in this example, you call REFind with a starting index of 8:
<cfset IndexOfOccurrence=REFind(" BIG ", "Some BIG BIG string", 8)>
<!--- The value of IndexOfOccurrence is 9 --->
In this case, the function returns an index of 9, the starting index of the second string " BIG ".
To find the second occurrence of the string, you must know that the first string occurred at index 5 and that the string's length was 5. However, REFind only returns starting index of the string, not its length. So, you either must know the length of the matched string to call REFind the second time, or you must use subexpressions in the regular expression.
The REFind and REFindNoCase functions let you get information about matched subexpressions. If you set these functions' fourth parameter, ReturnSubExpression, to True, the functions return a CFML structure with two arrays, pos and len, containing the positions and lengths of text strings that match the subexpressions of a regular expression, as the following example shows:
<cfset sLenPos=REFind(" BIG ", "Some BIG BIG string", 1, "True")>
<cfoutput>
<cfdump var="#sLenPos#">
</cfoutput><br>
The following figure shows the output of the cfdump tag:
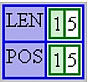
Element one of the pos array contains the starting index in the search string of the string that matched the regular expression. Element one of the len array contains length of the matched string. For this example, the index of the first " BIG " string is 5 and its length is also 5. If there are no occurrences of the regular expression, the pos and len arrays each contain one element with a value of 0.
You can use the returned information with other string functions, such as mid. The following example returns that part of the search string matching the regular expression:
<cfset myString="Some BIG BIG string">
<cfset sLenPos=REFind(" BIG ", myString, 1, "True")>
<cfoutput>
#mid(myString, sLenPos.pos[1], sLenPos.len[1])#
</cfoutput>
Each additional element in the pos array contains the position of the first match of each subexpression in the search string. Each additional element in len contains the length of the subexpression's match.
In the previous example, the regular expression " BIG " contained no subexpressions. Therefore, each array in the structure returned by REFind contains a single element.
After executing the previous example, you can call REFind a second time to find the second occurrence of the regular expression. This time, you use the information returned by the first call to make the second:
<cfset newstart = sLenPos.pos[1] + sLenPos.len[1] - 1>
<!--- subtract 1 because you need to start at the first space --->
<cfset sLenPos2=REFind(" BIG ", "Some BIG BIG string", newstart, "True")>
<cfoutput>
<cfdump var="#sLenPos2#">
</cfoutput><br>
The following figure shows the output of the cfdump tag:

If you include subexpressions in your regular expression, each element of pos and len after element one contains the position and length of the first occurrence of each subexpression in the search string.
In the following example, the expression [A-Za-z]+ is a subexpression of a regular expression. The first match for the expression ([A-Za-z]+)[ ]+, is "is is".
<cfsetsLenPos=REFind("([A-Za-z]+)[ ]+\1",<cfoutput> <cfdump var="#sLenPos#"> </cfoutput><br>
"There is is a cat in in the kitchen", 1, "True")>
The following figure shows the output of the cfdump tag:

The entries sLenPos.pos[1] and sLenPos.len[1] contain information about the match of the entire regular expression. The array elements sLenPos.pos[2] and sLenPos.len[2] contain information about the first subexpression ("is"). Because REFind returns information on the first regular expression match only, the sLenPos structure does not contain information about the second match to the regular expression, "in in".
The regular expression in the following example uses two subexpressions. Therefore, each array in the output structure contains the position and length of the first match of the entire regular expression, the first match of the first subexpression, and the first match of the second subexpression.
<cfset sString = "apples and pears, apples and pears, apples and pears"> <cfset regex = "(apples) and (pears)"> <cfset sLenPos = REFind(regex, sString, 1, "True")> <cfoutput> <cfdump var="#sLenPos#"> </cfoutput><br><br>
The following figure shows the output of the cfdump tag:
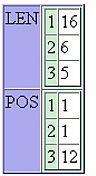
For a full discussion of subexpression usage, see the sections on REFind and REFindNoCase in the ColdFusion functions chapter in CFML Reference.